Hi,
In Energy Logserver, since indices are most often created daily, we usually transfer them to dedicated nodes, equipped with slower, but larger disks. The whole mechanism is called allocation and is based on attributes, which is something similar to tags.
Each Energy Logserver Data Node receives attribute, which defines if it's HOT, WARM or COLD. Those attributes are written in database config file:
## Cluster
cluster.name: logserver
node.name: node-1
node.master: true
node.data: true
node.attr.tag: hot
Now, the second step of this process is to tag new incoming data to be assigned to hot nodes. We do that by creating universal template, which applies to all new data and gives a allocation require tag parameter. This basically means that cluster knows, that this particular index has to be kept on the Data Nodes with matching allocation tag:
{
"order": 999,
"index_patterns": [
"*"
],
"settings": {
"index": {
"routing": {
"allocation": {
"require": {
"tag": "hot"
}
}
}
}
},
"mappings": {},
"aliases": {}
}
Last and final step is to create a scheduled task, which updates the allocation tag in the index settings, when index age is past certain point (14 days in example below). We do this with Index Management module with Custom action:
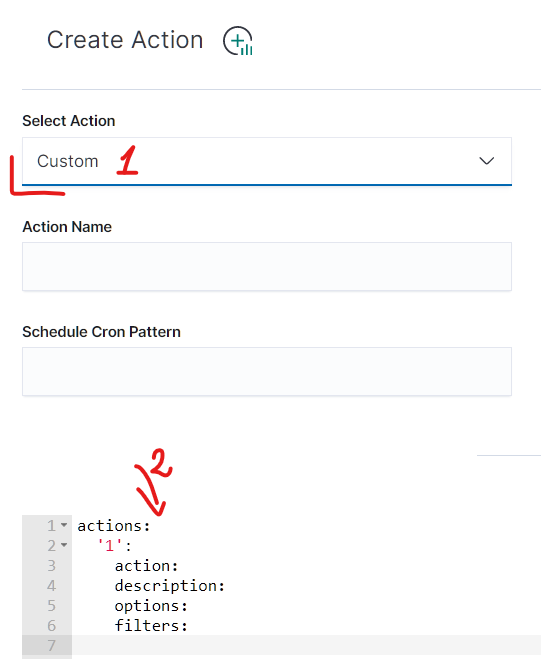
action:
'1':
action: allocation
description: >-
Apply shard allocation routing to 'include' 'tag=cold' for hot/cold node
setup for windows-winlogbeat- indices older than 14 days, based on name
date
options:
key: tag
value: cold
allocation_type: include
wait_for_completion: true
timeout_override:
filters:
- filtertype: pattern
kind: prefix
value: windows-winlogbeat-
exclude:
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 14
After that Index Management will change the tag of older indices. After that you don't have to do anything, because the cluster by itself will move shards to the correct Data Nodes.
Hope that this clarifies the process. If you'll have any further questions, let me know. 🙂